

DMTN-169
A model for Butler registry access control#
Abstract
Butler manages read and write access to Rubin Observatory data. Different types of data require different access control rules (Data Release versus User Generated data products, for example). Butler itself also needs a backing SQL database to store its information, which should be protected from unauthorized modification. This technote proposes a design for access control for both Butler queries and for data upload and download mediated by Butler.
Note
This is part of a tech note series on identity management for the Rubin Science Platform. The primary documents are DMTN-234, which describes the high-level design; DMTN-224, which describes the implementation; and SQR-069, which provides a history and analysis of the decisions underlying the design and implementation. See the references section of DMTN-224 for a complete list of related documents.
Current state#
Butler is a Python library that mediates access to Rubin Observatory data. It uses a SQL database, via SQLAlchemy, to store metadata about files. That database can either be a local SQLite database or a remote SQL database.
When a Rubin Science Platform user wants to process some data, they would call Butler to access the data, perform whatever processing they wish, and then call Butler again to store the results somewhere for future use. This requires the user running Butler to have direct access to the backing SQL database used by Butler. This database is called the registry. For Data Release data products, the Butler registry will be a central SQL database.
Users are expected to want to perform Butler queries that combine results from a Data Release with results from User Generated data products (their own or those of collaborators). Butler uses a single database for both types of data products so that it can perform these sorts of queries easily.
Therefore, to run Butler, users must have credentials with access to the database for the Butler registry. To store or retrieve files, users must also have credentials with access to those files.
Constraints#
Requirements#
Users must be able to query the combination of Data Release and User Generated data products using Butler.
Users must be able to download data products to which they have access, including the Data Release, and upload their own User Generated data products.
Users must not have access to User Generated data products or the registry entries for those products unless they have been granted access by the owners of those User Generated data products (either directly or via group membership).
Data downloads and uploads should be done directly from the data storage (GCS or another object data store), not mediated by a service, for performance reasons.
Design principles#
Granting every Science Platform user direct SQL access to the database underlying Butler is not desirable for both security and complexity reasons. Databases have a large attack surface, and access control restrictions in databases can be complex and tedious to manage.
Creating accounts for each user in the underlying object data store is more feasible but still not ideal for similar complexity reasons.
Creating Google Cloud Platform users for each user of the Science Platform is undesirable from both an identity management complexity perspective and for security reasons given the additional attack surface this exposes to compromised user accounts.
Minimizing the number of access control systems is preferable for security. Each separate access control system is another place where users have to be onboarded and offboarded, and where a misconfiguration can cause unexpected results. Ideally, as many access control decisions as possible are made in one place.
Proposed design#
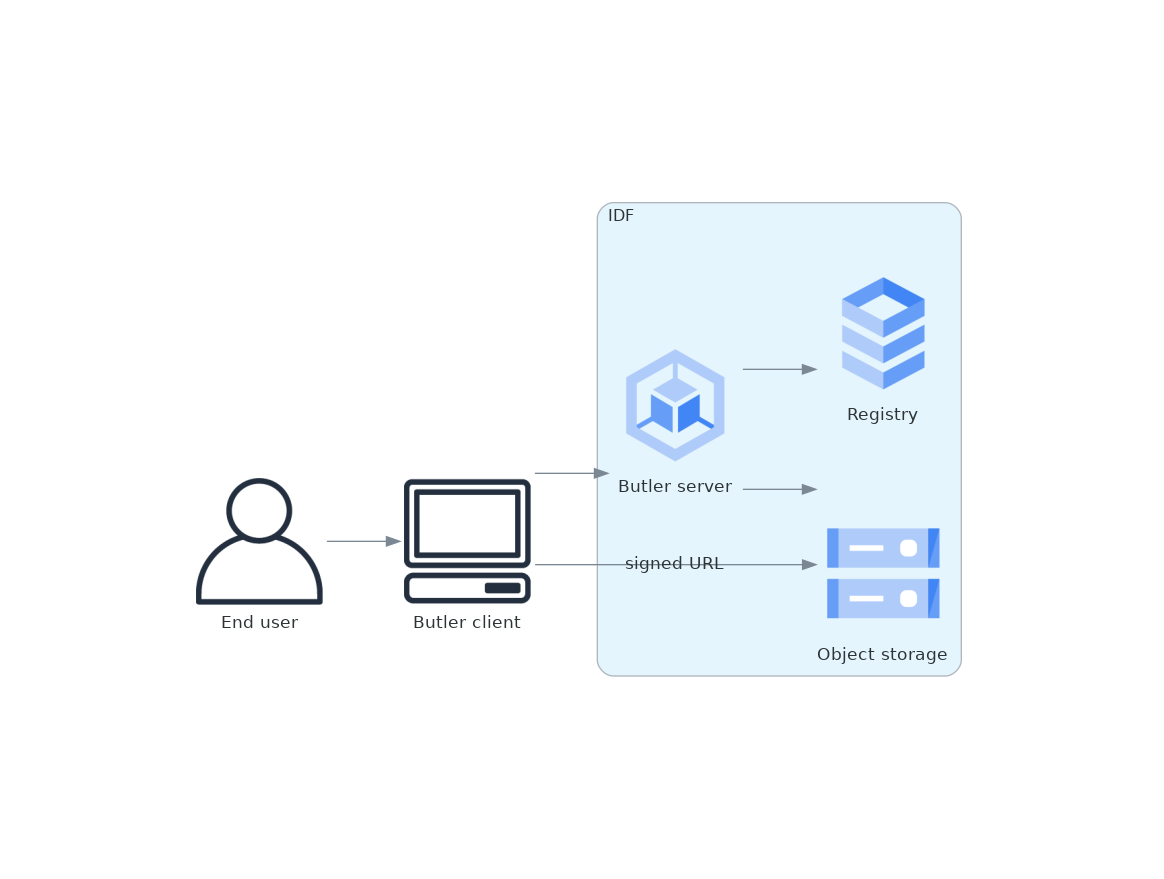
Separate the Butler into a server and a client. The current implementation, which uses direct SQL access, will be the core of the server. In front of that, add a shim that translates REST API calls to API calls into Butler, accepting parameters in JSON and serializing the results as JSON. Add a client that translates the current Butler API into REST API calls to that server. Use Gafaelfawr to authenticate the client API calls to the server.
In the server, use the user identity provided by Gafaelfawr in the request to construct the SQL queries such that data products not visible to the user are not queried or returned.
For data that is stored in an object store (as opposed to an accessible POSIX file system), transform GCS URLs that would be returned by Butler to signed download URLs. This will allow the client to download the data without requiring its own GCS credentials.
This assumes that any object storage system used in other Rubin Observatory Data Facilities will also support signed URLs. They are supported by GCS, Amazon S3, and Ceph.
Alternately, if there are a large number of such URLs in a typical reply or if the client normally doesn’t use most URLs, this can be optimized by adding another API call. Return GCS URLs or some equivalent pointer than then add a new API call to convert them to signed URLs on demand, and add code to the client to do that conversion before using a GCS URL.
For data storage, the client would use the following process:
Make an API call to Butler (via a client library that makes a REST API call) indicating that the client wants to store some data and providing metadata.
The Butler API would return a signed URL for the upload.
Upload the data directly to GCS or some other object store.
Tell Butler that the upload is complete, at which point Butler can perform any needed verification and commit the associated metadata.
In this design, all access control decisions are concentrated in the Butler server, and only the Butler server needs object store credentials or SQL database access. A single SQL database can continue to be used for both Data Release and User Generated data products without complex database ACLs.
Drawbacks#
The Butler service, in this design, takes on the additional complexity of full responsibility for access control decisions beyond the simple “is this a valid Science Platform user” check performed by Gafaelfawr. However, the alternative is to materialize the same rules as ACLs in GCS and in a SQL database, which would mean somewhat more complexity. In that alternate design, access control rules would live in two different systems plus the synchronization code to maintain those rules.
Requiring serialization and deserialization of the results of SQL queries and an additional hop through the Butler REST service will somewhat reduce performance and add some additional complexity compared to making direct SQL queries.
This design does not solve the problem of merging results from an offline, local registry and the primary Rubin Observatory registry. It instead moves in the opposite direction towards preferring a single unified registry, and thus preferring all Butler actions be done online with connectivity to the Butler service.
Butler can work with local files, but it’s not clear how best to represent that in this model of combined registry. Users could store local path names in the portion of the central registry dedicated to their private work, but this is somewhat inelegant given the inherent ambiguity about what those paths represent. Alternately, users could use a local SQLite Butler registry for that purpose, but this again introduces the problem of how to work with both the primary Rubin Observatory Butler registry and those local registries.
Interim design for DP0.1#
The new client/server design is more work than makes sense to tackle prior to DP0.1. However, DP0.1 will involve a smaller group of users than the eventual Science Platform users and therefore poses fewer security concerns.
Therefore, DP0.1 can use the existing Butler implementation. To support the desired query behavior, that Butler implementation should use a central SQL database with information for both the Data Release and User Generated data products. Every Science Platform user will be given credentials, via the notebook environment, for that database that will have read access to the Data Release registry and read/write access to all User Generated data product registries. Similarly, every Science Platform user will be given GCS credentials with read-only access to all Data Release products and read/write access to storage space for User Generated products.
This means that every Science Platform user for the DP0.1 release will have full access to the data of all other Science Platform users. For this early test release, we will rely on good faith, collaboration, and the small user base rather than formal access controls.